
LLMs can perform impressive role play but due to their lack of short term memory, things go off the rails quickly. We set out to see if we could improve on this with prompt engineering alone. Read our case study.
Starship bridge is a text-based role playing game where you take the role of captain on the bridge of a starship. You have three crew on the bridge with you and the adventure can go off in any direction you wish.
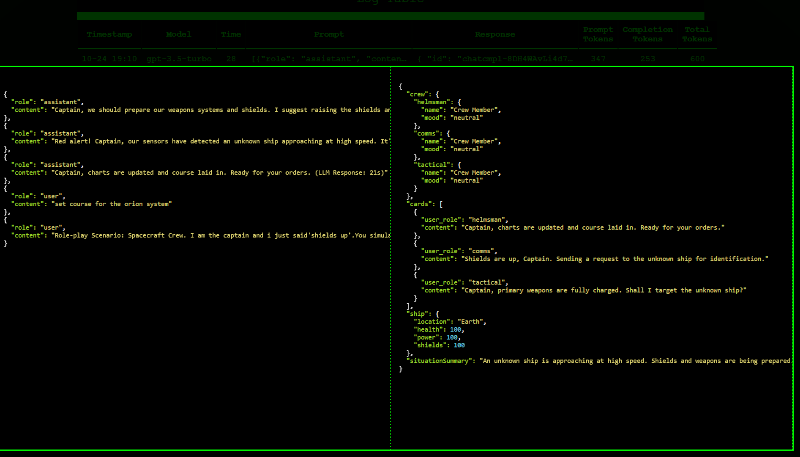
We created a json object to represent this simple role playing scenario on the bridge of a starship. We created starting values in this json, and then provided it to the LLM, asking it to update and return the JSON. In this way we simulated a permanent data store.

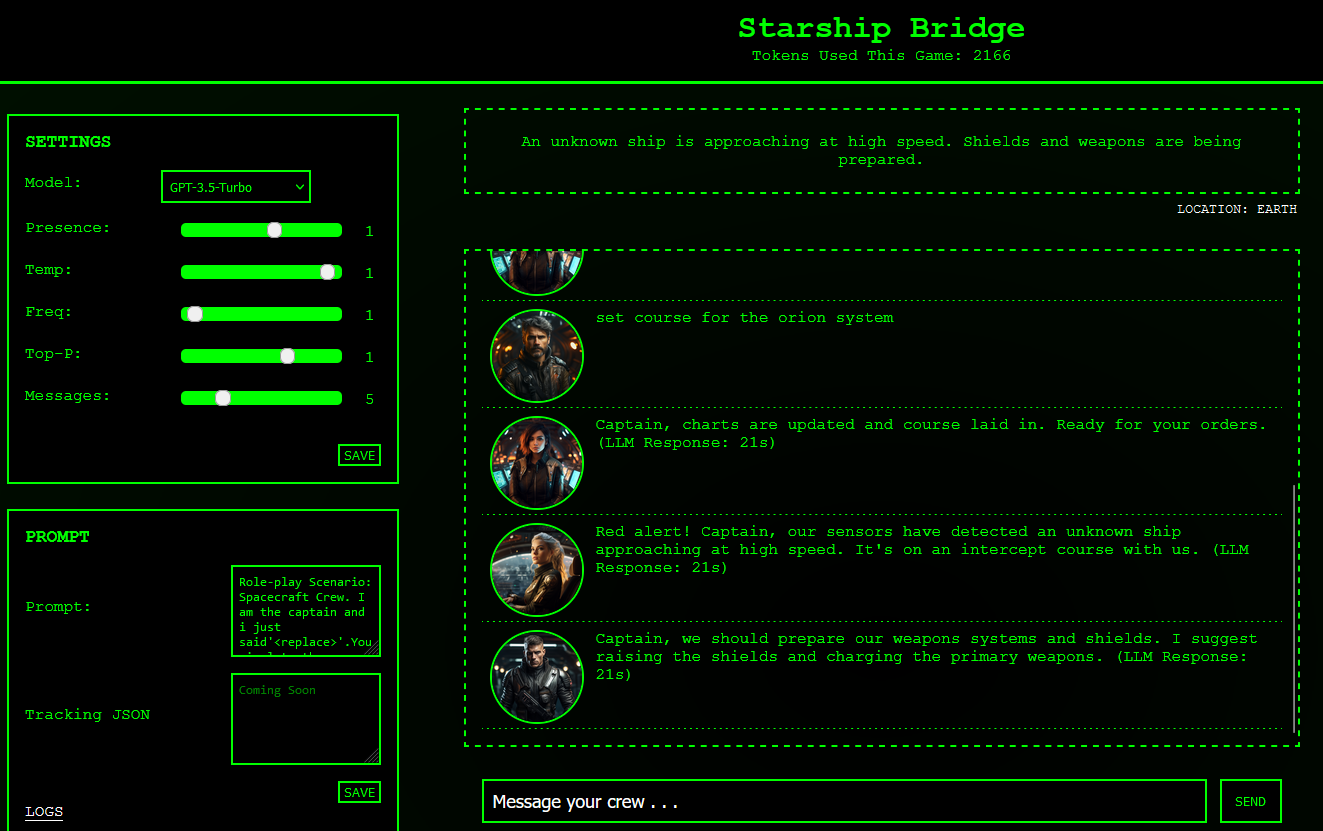
This app has a model selector and a configuration panel for adjusting model parameters. It also has a standardized json file that get passed to and (hopefully) passed back by the LLM.
We used a simple Django website running on AWS Elastic Container Service, communicating directly with the OpenAI API. We had originally hoped to have an enrichment pipeline, but this proved to be too slow for the core loop.
The main problem with the game is performance and we would like to test this with different models and hosting configurations. The current response times are far too slow for this to be a compelling game.